[Note as of 3/24/24: The technology here known as "Mem X" is now simply called "Mem"]
Over the course of our lives, we spend a vast amount of time creating and capturing information. Yet we lack the ability to usefully draw from this well of knowledge, as it often becomes lost in folders or information silos.
At Mem, we are building a world in which every person has access to the information they need when they need it. We leverage AI technology to create a self-organizing workspace that automatically organizes all of the information in your work life and proactively surfaces relevant knowledge.
Our long-term mission is to unlock the collective intelligence of humanity. To realize our vision for the future, we are harnessing a technological inflection point: the quality of publicly available foundation models.
Recent breakthroughs in large language models (LLMs) like GPT-3 have drastically changed the field of Natural Language Processing (NLP). Unlike previous generations of NLP that required the construction of separate models for each specific language task, these LLMs are not specialized for any particular task. With a small amount of fine-tuning, we have been able to optimize these pre-trained LLMs for our own use cases.
Most recently, creators of LLMs have also started to open up their black boxes, releasing access to internal layers from within those models. OpenAI’s embeddings models, for example, allow users to access the embedding layers that encode a text’s meaning, giving more insight into the fundamental building blocks of their NLP AI than the direct GPT-3 output alone can provide. Embeddings are high-dimensional vectors that encode different features of text documents, including meaning, structure, content, theme and topic. Texts with similar meanings will have similar vector representations, and by comparing embeddings of different pieces of text, we can measure the similarity between them. Embeddings make natural language tasks such as semantic search and clustering of similar documents easy to perform.
The ability to carry out these similarity calculations at query time is critical when building products that rely on embeddings. Pinecone is a leader in the vector search space, and their vector database allows users to store embeddings and quickly query for similar embeddings based on various similarity measures and filters.
We leverage both OpenAI embeddings models and Pinecone vector search as fundamental pillars of Mem X. These technologies power features such as similar mems and smart results, among others. Similar mems surfaces documents that are semantically similar to the document a user is viewing, allowing users to discover knowledge from across their team, re-discover knowledge they forgot they had, and make new connections between pieces of information they might not have otherwise seen. Smart results allows users to ask Mem questions as though it were a person – e.g., “How many people did we add to the Mem X waitlist in March?”. With smart results, Mem understands the semantic meaning of a user's search query and then finds the most relevant results.
OpenAI offers different embeddings models specialized for different functionalities. We use the text similarity and text search models. The similarity embeddings are good at capturing semantic similarity between multiple pieces of text, and the text search embeddings are trained to measure whether long documents are relevant to a short search query.
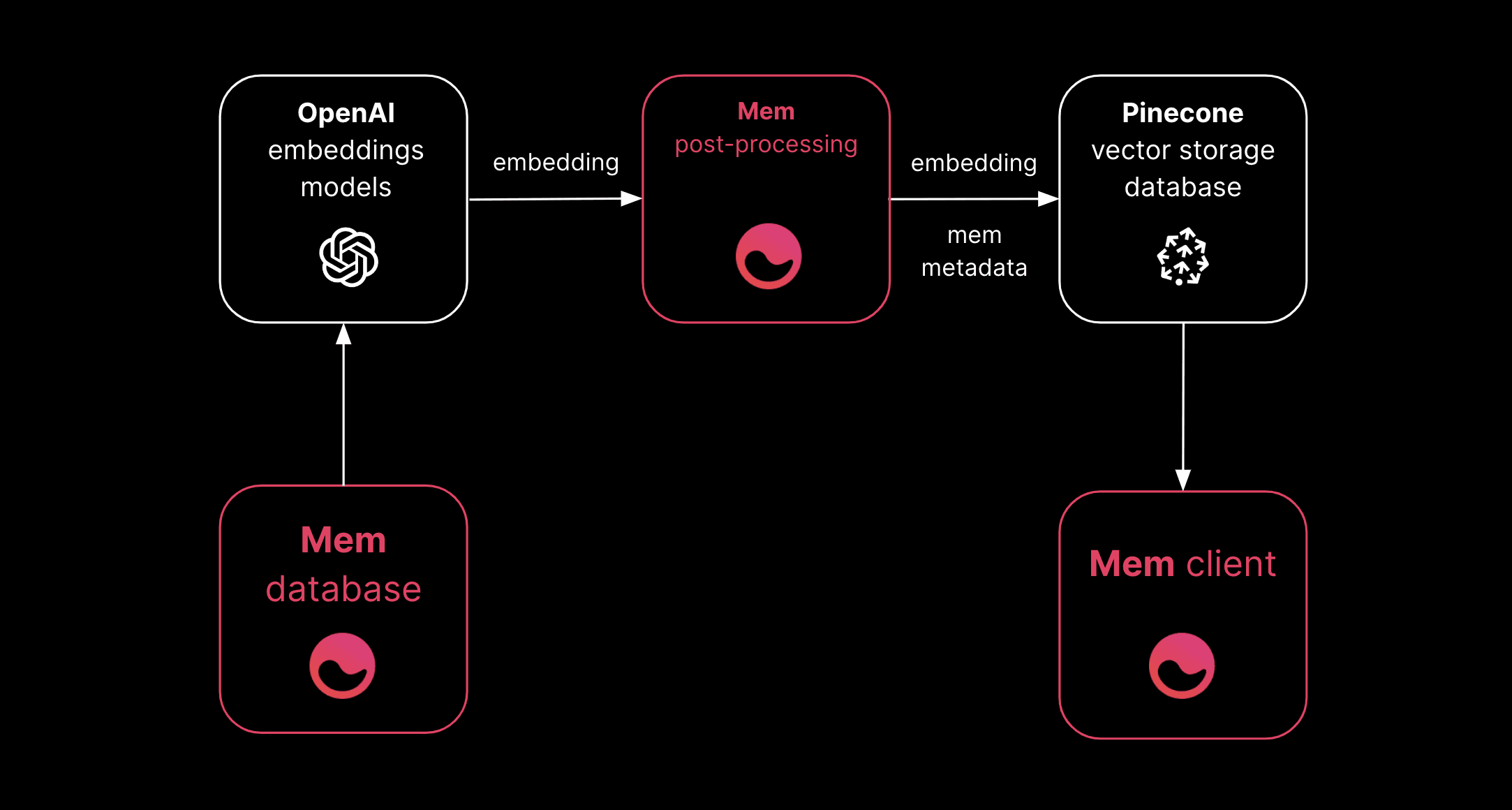
We transform each document into a format that can be embedded, and use OpenAI's embeddings API to create two embeddings for the document, one with a similarity model and the other with a search model. The embeddings are stored in a Pinecone index, along with metadata about the document. We leverage Pinecone's namespaces to create divisions between vectors that are produced by different models. As a user edits a document, we continuously re-compute the embeddings for this document and upsert the new embeddings to the Pinecone index to ensure that our embeddings are always up to date.
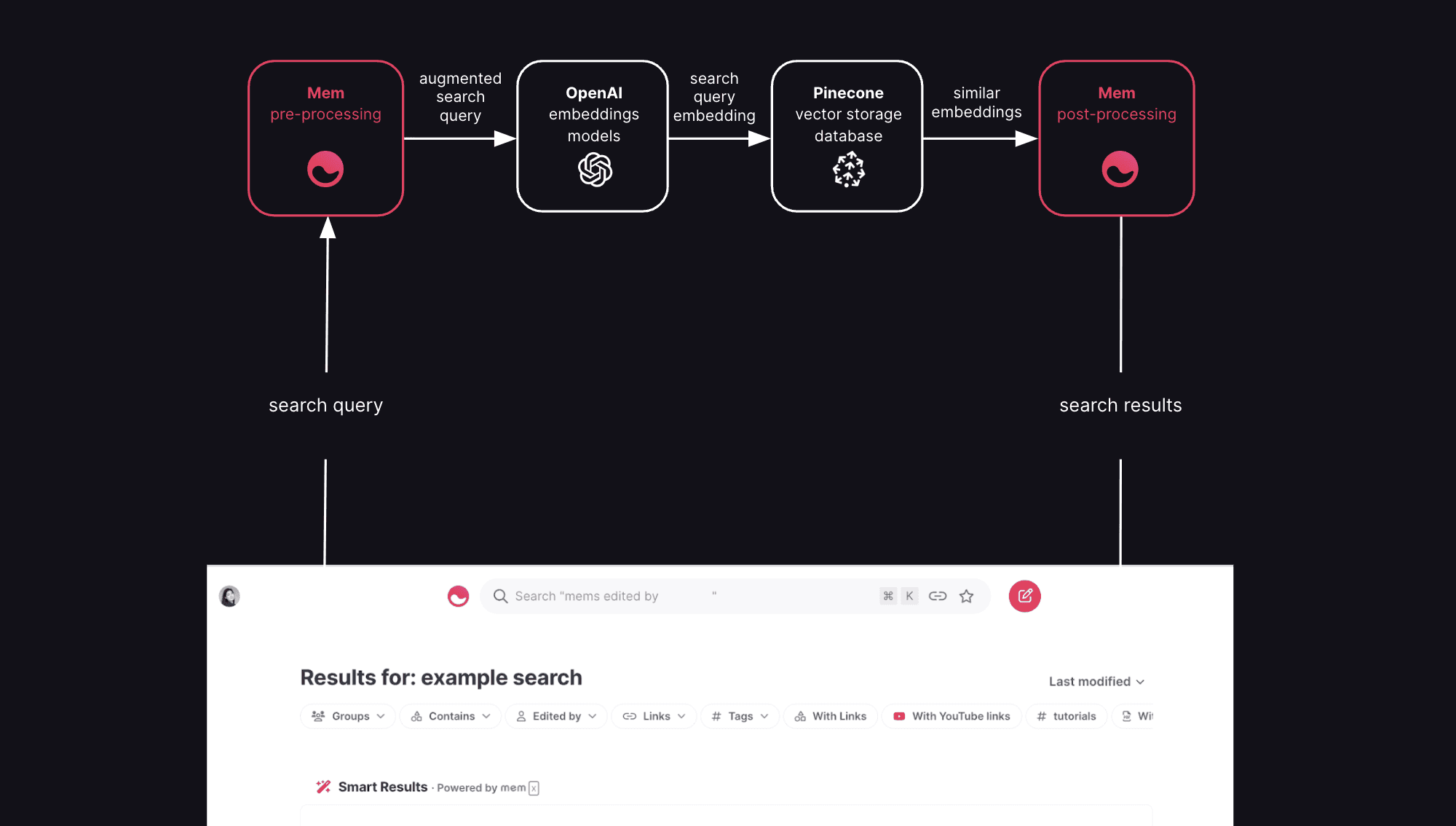
In the case of smart results, when a user makes a search, we parse and transform the search query before creating an embedding with one of OpenAI's search query models, and then query the Pinecone index to find the most similar search documents (i.e. documents with the highest cosine similarity score). Pinecone's metadata filtering functionality allows us to query for only those embeddings that represent documents to which the currently signed-in user has access. We then reconcile the search results returned from Pinecone with our non-semantic search service to improve keyword results, and display the documents corresponding to these embeddings.
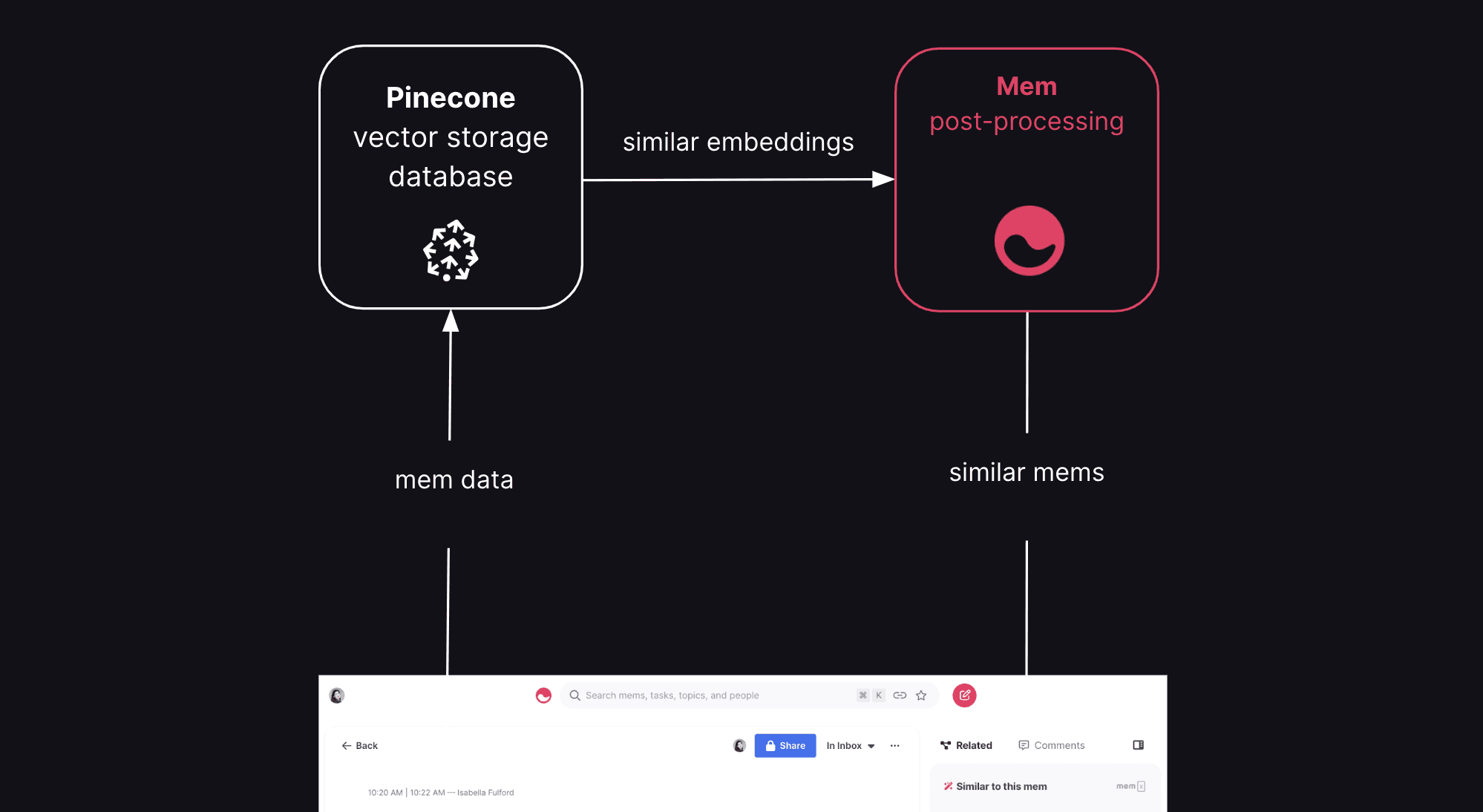
In the Similar Mems feature, when a user views a document, we fetch the embedding for the document from the Pinecone index, then query the index for the most similar embeddings according to metadata filters. We re-rank and re-weight these similar embeddings based on our own clustering and length normalization algorithms, and surface the documents that the embeddings most closely correspond to.
Over time, we will be able to automatically organize all of the information that exists within an organization, from employee information to customer data, internal documents, research, emails, Slack messages, and more.
Learn More:
Educational materials: